| 参数 | 描述 | 默认值 |
|---|---|---|
| source | 设置爬虫。 | google_search |
| query | 要搜索的关键词或短语。 | - |
| context: udm | 要获取新闻搜索结果,请将 value 设置为 12。 查找其他接受的值 here. | |
| context: tbm | 要获取新闻搜索结果,请将 value 设置为 nws. 其他接受的值有: app, blg, bks, dsc, isch, pts, plcs, rcp, lcl | - |
render | 当设置为时启用 JavaScript 渲染 html. 更多信息. | - |
parse | 当设置为时返回解析后的数据 true。查看输出 数据字典. | false |
callback_url | 回调端点的 URL。 更多信息. | - |
user_agent_type | 设备类型和浏览器。完整列表可在 here. | desktop |
| 参数 | 描述 | 默认值 |
|---|---|---|
geo_location | 应适配结果的地理位置。正确使用此参数对于获取正确数据非常重要。有关更多信息,请阅读我们建议的 geo_location 参数结构 here. | - |
locale | Accept-Language 标头值,用于更改您 Google 搜索页面的网页界面语言。 更多信息. | - |
| 参数 | 描述 | 默认值 |
|---|---|---|
start_page | 起始页码。 | 1 |
pages | 要检索的页数。 | 1 |
limit | 每页要检索的结果数量。 | 10 |
| 如果您想用相同 IP 抓取多个页面,请包含一个 JSON 数组并使用 page 键 指定页码。您还必须通过添加一个 limit 键 来指明每页的自然结果数量。 见示例. | - |
| 参数 | 描述 | 示例 |
|---|---|---|
page | 您要抓取的页码。任何大于 0 的整数值都可用 | 1 |
limit | 相关页的结果数量。任何介于 1 和 100 (含)之间的整数值都可用。 | 90 |
| 参数 | 描述 | 默认值 |
|---|---|---|
context:safe_search | 安全搜索。设置为 true 以启用它。 | false |
context:tbs | tbs 参数。该参数类似于一个容器,用于更晦涩的 Google 参数,例如按日期限制/排序结果,以及其他某些依赖于 tbm 参数(例如 tbs=app_os:1 仅在与 tbm 值 app一起使用时可用)。更多信息 here. | - |
| 参数 | 描述 | 默认值 |
|---|---|---|
context:nfpr | true 将关闭拼写自动更正 | false |
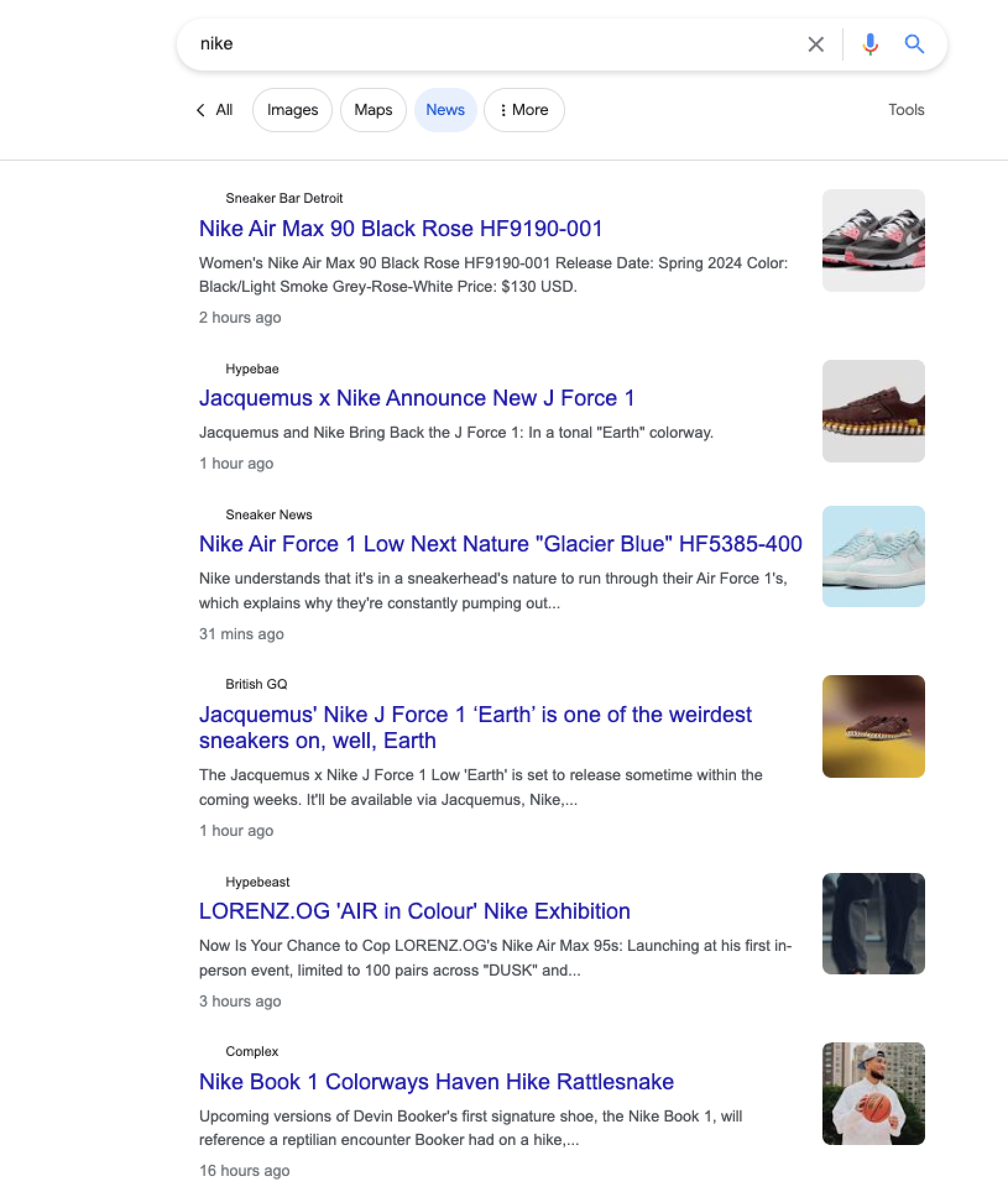
google_search news 结构化输出| 键 | 描述 | 类型 |
|---|---|---|
url | Google 搜索页面的 URL。 | 字符串 |
结果 | 包含搜索结果的字典。 | 数组 |
results.main | 一列未付费新闻结果及其各自的详细信息。 | 数组 |
results.additional | 一列热门文章及其各自的详细信息。 | 对象 |
results.total_results_count | 搜索查询找到的结果总数。 | 数组 |
parse_status_code | 解析任务的状态代码。您可以在此处查看解析器状态代码的描述 here. | 整数 |
created_at | 抓取任务创建的时间戳。 | timestamp |
updated_at | 抓取任务完成的时间戳。 | timestamp |
page | 相对于 Google SERP 分页的页面编号。 | 整数 |
job_id | 与抓取任务关联的作业 ID。 | 字符串 |
status_code | 抓取任务的状态代码。您可以在此处查看抓取器状态代码的描述 here. | 整数 |
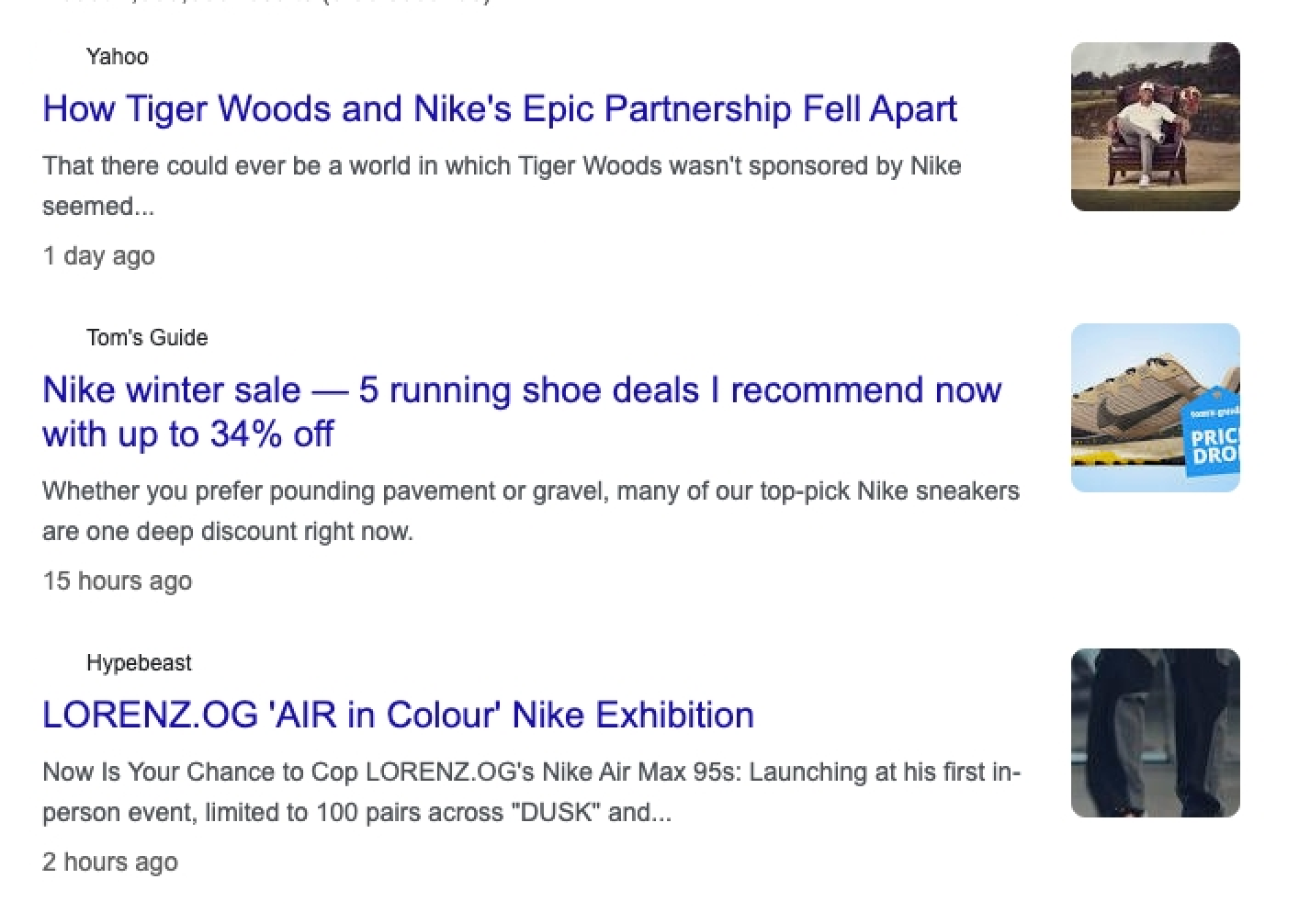
| 键 (results.main) | 描述 | 类型 |
|---|---|---|
url | 完整文章的 URL。 | 字符串 |
desc | 文章正文的简短摘录。 | 字符串 |
title | 文章的标题。 | 字符串 |
source | 文章发布的网站名称。 | 字符串 |
pos_overall | 表示该结果在新闻 SERP 主结果中的整体位置。 | 整数 |
relative_publish_date | 描述文章发布的距离当前时间。 | 字符串 |
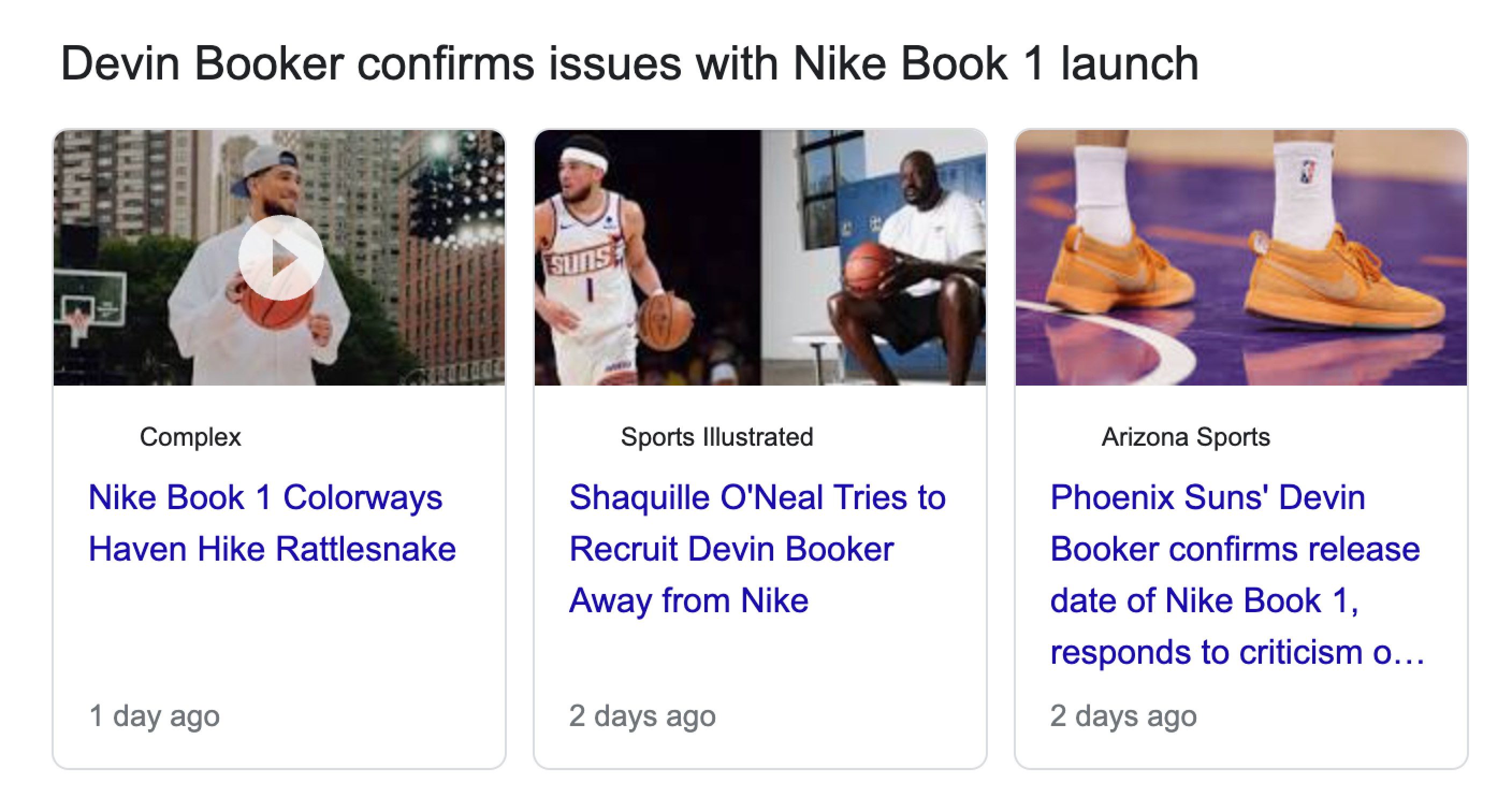
| 键 (results.additional) | 描述 | 类型 |
|---|---|---|
项目 | 带有各自详细信息的文章列表。 | 数组 |
items.pos | 表示文章在列表中的唯一位置标识。 | 整数 |
items.url | 完整文章的 URL。 | 字符串 |
items.title | 文章的标题。 | 字符串 |
items.source | 文章发布的网站名称。 | 字符串 |
items.relative_publish_date | 描述文章发布的距离当前时间。 | 字符串 |
pos_overall | 表示该结果在新闻 SERP 附加结果中的整体位置。 | 整数 |
section_title | 附加部分的名称。 | 字符串 |