# Primeiros passos
## Como usar o Custom Parser
### Exemplo de cenário
Suponha que você queira analisar o **número de resultados totais** que o Bing Search retorna com um termo de busca `test`:
Vamos apresentar as três principais maneiras de alcançar esse objetivo:
* [Gerar parsers com OxyCopilot](#generate-parsers-with-oxycopilot)
* [Gerar parsers via API](#generate-parsers-via-api)
* [Escrever instruções de parsing manualmente](#write-instructions-manually)
### Gerar parsers com OxyCopilot
OxyCopilot permite que você descreva suas necessidades em inglês simples para **criar automaticamente scrapers e parsers** para um site. Aprenda o básico seguindo os passos abaixo e consulte [documentação do OxyCopilot](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api-playground/oxycopilot#custom-parser-builder) para mais informações.
{% hint style="success" %}
Abra o [**Web Scraper API Playground**](https://dashboard.oxylabs.io/en/api-playground) no nosso painel para acessar o OxyCopilot.
{% endhint %}
{% stepper %}
{% step %}
#### Insira a(s) URL(s)
Clique no **botão OxyCopilot** no canto superior esquerdo e insira até 3 URLs do mesmo tipo de página. Vamos usar esta URL do Bing Search: `https://www.bing.com/search?q=test`.
{% hint style="info" %}
Você também pode configurar o scraper manualmente preenchendo os **Site**, **campos Scraper**, e **URL** no topo, e ajustando **parâmetros adicionais** como renderização JavaScript no menu lateral esquerdo.
{% endhint %}
{% endstep %}
{% step %}
#### Configurar parâmetros do scraper
Em seguida, especifique os parâmetros do scraper, instruções do navegador e habilite a renderização JavaScript se o site alvo exigir.
Para o Bing Search, **habilite a renderização JavaScript** e então clique **Próximo**.
{% endstep %}
{% step %}
#### Escreva o prompt
Explique os dados que você deseja extrair de uma página. Certifique-se de ser descritivo e fornecer as informações mais importantes. Você pode encontrar exemplos de prompts para sites populares em nossa [biblioteca de prompts do OxyCopilot](https://oxylabs.io/resources/prompts-code-samples).
Cole o prompt a seguir para extrair o número total de resultados das páginas do Bing Search:
```
Analise o número total de resultados de pesquisa.
```
Clique no **Gerar instruções** botão para enviar seu prompt.
{% endstep %}
{% step %}
#### Revisar dados e instruções parseados
Quando o OxyCopilot terminar, você verá a seguinte janela onde os dados parseados estão à direita:
Se quiser fazer ajustes, você pode fazê‑los aqui. Modifique a(s) URL(s), refine o prompt, habilite a renderização Javascript, ou [edite o esquema de parsing](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api-playground/oxycopilot#step-2-optional-adjust-parsing-schema) para atender às suas necessidades. Quando você atualizar qualquer campo nesta janela, pode executar a solicitação novamente selecionando **Iniciar nova solicitação**.
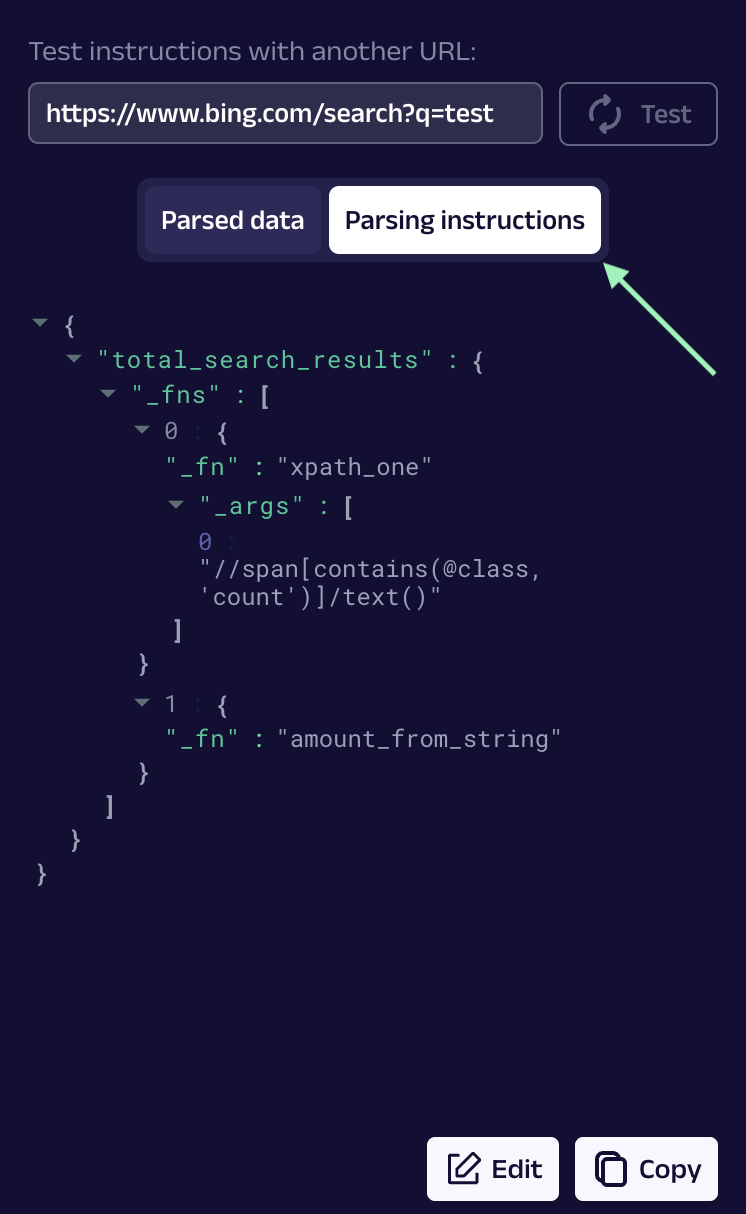
Você também pode **visualizar e editar diretamente as instruções de parsing** aqui:
Quando estiver satisfeito com o resultado, **Carregar instruções** para continuar.
{% endstep %}
{% step %}
#### Salvar o parser como um preset
Você pode facilmente salvar suas instruções de parsing como um [preset de parser](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api/features/custom-parser/parser-presets). Isso permite reutilizar o preset no OxyCopilot e em suas requisições de API.
No Web Scraper API Playground, você pode opcionalmente escolher o usuário para o qual salvar o preset. Quando estiver tudo pronto, simplesmente clique em **Salvar**:
Um pop-up aparecerá solicitando que você nomeie o preset e adicione uma descrição opcional:
{% endstep %}
{% step %}
#### Usar o preset com requisições de API
Para usar um preset com suas requisições da Web Scraper API, defina `parse` to `true` e especifique o nome do preset com o `parser_preset` nfpr
**Endpoint:** `POST https://data.oxylabs.io/v1/queries`
```json
{
"source": "bing_search",
"query": "test",
"render": "html",
"parse": true,
"parser_preset": "Bing_total_results"
}
```
Executar a requisição fornecerá o seguinte output JSON:
```json
{
"results": [
{
"content": {
"parse_status_code": 12000,
"total_search_results": 12000000
},
"created_at": "2025-10-24 09:29:28",
"updated_at": "2025-10-24 09:30:42",
"page": 1,
"url": "https://www.bing.com/search?q=test",
"job_id": "7387419953164488705",
"is_render_forced": false,
"status_code": 200,
"type": "parsed",
"parser_type": "preset",
"parser_preset": "Bing_total_results"
}
]
}
```
{% endstep %}
{% endstepper %}
## Uso avançado
### Gerar parsers via API
Em vez de usar o OxyCopilot no playground, você pode enviar prompts diretamente para a Web Scraper API e gerar parsers. Veja a [Gerando instruções de parsing via API](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api/features/custom-parser/generating-parsing-instructions-via-api) página de documentação para saber mais.
{% hint style="success" %}
Recomendamos **fornecer 3-5 URLs do mesmo tipo** (por exemplo, páginas de produto). Isso ajuda o parser a se adaptar a diferentes layouts e melhora a precisão do parsing.
{% endhint %}
**Endpoint:** `POST https://data.oxylabs.io/v1/parsers/generate-instructions/prompt`
```json
{
"prompt_text": "Parse the number of total search results.",
"urls": ["https://www.bing.com/search?q=test"],
"render": true
}
```
Saída
```json
{
"parsing_instructions": {
"total_search_results": {
"_fns": [
{
"_args": [
"//span[contains(@class, 'count')]/text()"
],
"_fn": "xpath_one"
},
{
"_fn": "amount_from_string"
}
]
}
},
"prompt_schema": {
"properties": {
"total_search_results": {
"description": "The number of total search results.",
"title": "Total Search Results",
"type": "number"
}
},
"required": [
"total_search_results"
],
"title": "Fields",
"type": "object"
}
}
```
### Salvar presets de parser via API
A Web Scraper API permite salvar instruções de parsing como presets de parser reutilizáveis. Confira a [documentação de Parser Presets](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api/features/custom-parser/parser-presets) para encontrar uma lista de ações disponíveis e exemplos de código abrangentes.
**Endpoint:** `POST https://data.oxylabs.io/v1/parsers/presets`
```json
{
"name": "Bing_total_results",
"parsing_instructions": {
"total_search_results": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [
"//span[contains(@class, 'count')]/text()"
]
},
{
"_fn": "amount_from_string"
}
]
}
}
}
```
Saída
```json
{
"id": 421938,
"name": "Bing_total_results",
"description": null,
"prompt_text": null,
"prompt_schema": null,
"urls": [],
"render": false,
"parsing_instructions": {
"total_search_results": {
"_fns": [
{
"_args": [
"//span[contains(@class, 'count')]/text()"
],
"_fn": "xpath_one"
},
{
"_fn": "amount_from_string"
}
]
}
},
"self_heal": false,
"heal_status": "disabled",
"last_healed_at": null,
"created_at": "2025-10-27 09:28:37",
"updated_at": "2025-10-27 09:28:37"
}
```
### Escrever instruções manualmente
Para usar o Custom Parser manualmente, inclua um conjunto de `parsing_instructions` ao criar um job. Você pode usar **seletores CSS e XPath** para direcionar elementos no DOM.
Siga o exemplo passo a passo abaixo para aprender o básico, depois explore nosso guia aprofundado sobre [escrever instruções manualmente](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api/features/custom-parser/writing-instructions-manually) para técnicas avançadas e documentação detalhada.
Vamos usar o cenário do Bing Search como exemplo. Os parâmetros do job ficariam assim:
```json
{
"source": "bing_search",
"query": "test",
"render": "html",
"parse": true,
"parsing_instructions": {
"number_of_results": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@class='sb_count']/text()"]
}
]
}
}
}
```
**Passo 1.** Você deve fornecer o `"parse": true` nfpr
**Passo 2.** As instruções de parsing devem ser descritas em `"parsing_instructions"` campo.
As instruções de parsing de exemplo acima especificam que o objetivo é analisar o número de resultados de pesquisa do documento raspado e colocar o resultado no `number_of_results` campo. As instruções sobre como analisar o campo definindo um “pipeline” são dadas como:
```json
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@class='sb_count']/text()"]
}
]
```
O pipeline descreve uma lista de funções de processamento de dados a serem executadas. As funções são executadas na ordem em que aparecem na lista e recebem a saída da função anterior como entrada.
No pipeline de exemplo acima, a `xpath_one` função ([**lista completa de funções disponíveis**](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/web-scraper-api/features/custom-parser/writing-instructions-manually/list-of-functions)) é usada. Ela permite processar um documento HTML usando expressões XPath e funções XSLT. Como argumento da função, especifique o caminho exato onde o elemento alvo pode ser encontrado: `.//span[@class='sb_count']`. Você também pode instruir o parser a selecionar o `text()` encontrado no elemento alvo.
O resultado parseado do job de exemplo acima deve ser parecido com isto:
```json
{
"results": [
{
"content": {
"number_of_results": "About 16,700,000 results",
"parse_status_code": 12000
},
"created_at": "2025-10-27 09:48:04",
"updated_at": "2025-10-27 09:48:38",
"page": 1,
"url": "https://www.bing.com/search?q=test",
"job_id": "7388511797231226881",
"is_render_forced": false,
"status_code": 200,
"type": "parsed",
"parser_type": "custom",
"parser_preset": null
}
]
}
```
O Custom Parser não só oferece extração de texto de um HTML raspado, como também pode executar funções básicas de processamento de dados.
Por exemplo, as instruções de parsing descritas anteriormente extraem `number_of_results` como um texto com palavras‑chave extras que você pode não precisar necessariamente. Se quiser obter o número de resultados para a `query=test` no tipo de dado numérico, você pode reutilizar as mesmas instruções de parsing e adicionar a `amount_from_string` função ao pipeline existente:
```json
{
"source": "bing_search",
"query": "test",
"render": "html",
"parse": true,
"parsing_instructions": {
"number_of_results": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@class='sb_count']/text()"]
},
{
"_fn": "amount_from_string"
}
]
}
}
}
```
O resultado parseado do job de exemplo acima deve ser parecido com isto:
```json
{
"results": [
{
"content": {
"number_of_results": 14200000,
"parse_status_code": 12000
},
"created_at": "2025-10-27 10:00:36",
"updated_at": "2025-10-27 10:01:05",
"page": 1,
"url": "https://www.bing.com/search?q=test",
"job_id": "7388514950961963009",
"is_render_forced": false,
"status_code": 200,
"type": "parsed",
"parser_type": "custom",
"parser_preset": null
}
]
}
```
## O que acontece se o parsing falhar ao usar o Custom Parser
Se o Custom Parser falhar ao processar instruções de parsing definidas pelo cliente, retornaremos o `12005` código de status (parseado com avisos).
```json
{
"source": "bing_search",
"query": "test",
"render": "html",
"parse": true,
"parsing_instructions": {
"number_of_results": {
"_fns": [
{
"_fn": "xpath_one",
"_args": [".//span[@class='sb_count']/text()"]
},
{
"_fn": "amount_from_string"
}
]
},
"number_of_organics": {
"_fns": [
{
"_fn": "xpath",
"_args": ["//this-will-not-match-anything"]
},
{
"_fn": "length"
}
]
}
}
}
```
Você será cobrado por tais resultados:
```json
{
"results": [
{
"content": {
"_warnings": [
{
"_fn": "xpath",
"_msg": "XPath expressions did not match any data.",
"_path": ".number_of_organics",
"_fn_idx": 0
}
],
"number_of_results": 14200000,
"parse_status_code": 12005,
"number_of_organics": null
},
"created_at": "2025-10-27 10:03:54",
"updated_at": "2025-10-27 10:04:22",
"page": 1,
"url": "https://www.bing.com/search?q=test",
"job_id": "7388515782126234625",
"is_render_forced": false,
"status_code": 200,
"type": "parsed",
"parser_type": "custom",
"parser_preset": null
}
]
}
```
Se o Custom Parser encontrar uma exceção e falhar durante a operação de parsing, ele pode retornar estes códigos de status: `12002`, `12006`, `12007`. Você não será cobrado por esses erros inesperados.
## Códigos de status
Veja nossos códigos de status descritos [**aqui**](https://developers.oxylabs.io/documentation/pt-br/solucoes-de-scraping/response-codes#parsers).