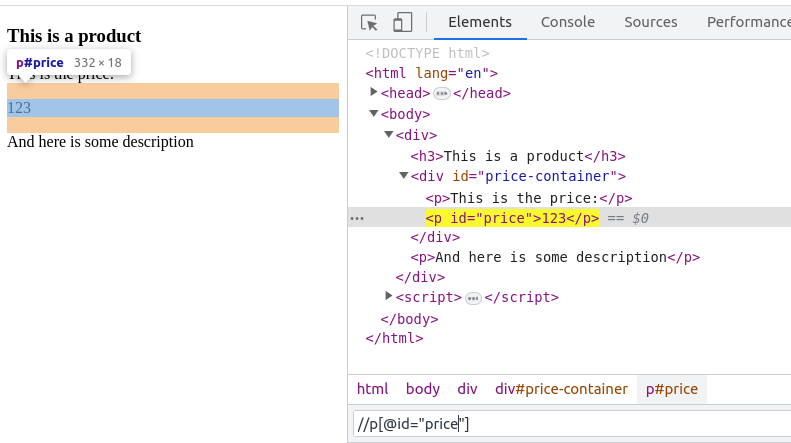
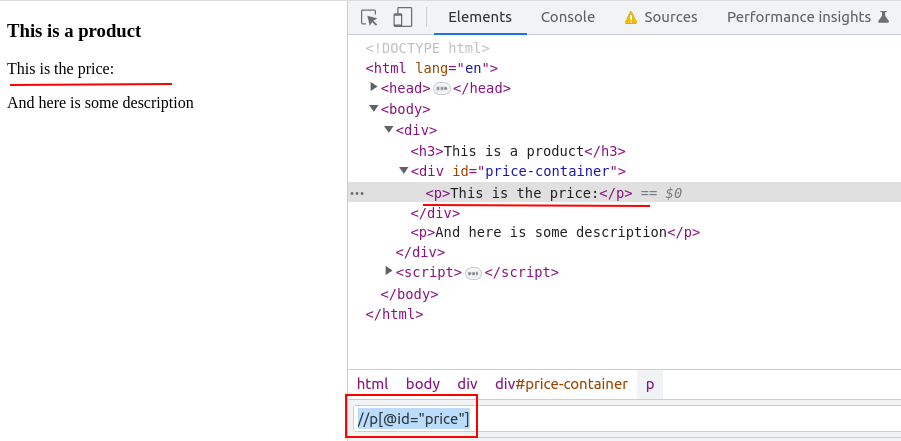
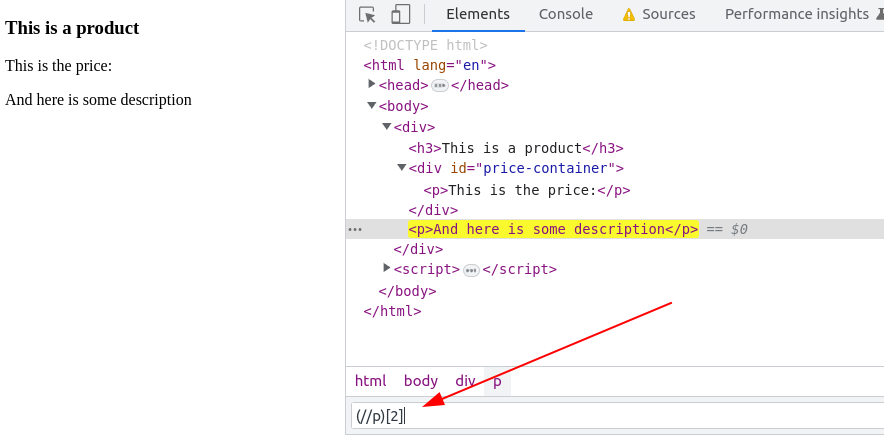
# 编写 XPath 表达式的技巧
## 抓取的文档与浏览器加载的文档之间的 HTML 结构可能不同
在编写 HTML 元素选择函数时, **请确保使用抓取到的文档,而不是你浏览器中加载的在线网站版本**,因为文档可能不同。造成此问题的主要原因是 JavaScript 渲染。当网站被打开时,浏览器负责加载额外的文档,例如 CSS 样式表和 JavaScript 脚本,这些都可能改变初始 HTML 文档的结构。在解析抓取的 HTML 时,Custom Parser 不会像浏览器那样加载 HTML 文档(解析器会忽略 JavaScript 指令),因此解析器与浏览器渲染的 HTML 树可能不同。
例如,请查看以下 HTML 文档:
```html
Document